One of my side projects is developing and maintaining an unofficial Prometheus Exporter for Rancher. It exposes metrics pertaining to Rancher-specific resources including, but not limited to managed clusters, Kubernetes versions, and more. Below shows an example dashboard based on these metrics.
Incidentally, if you are using Rancher, I’d love to hear your thoughts/feedback.
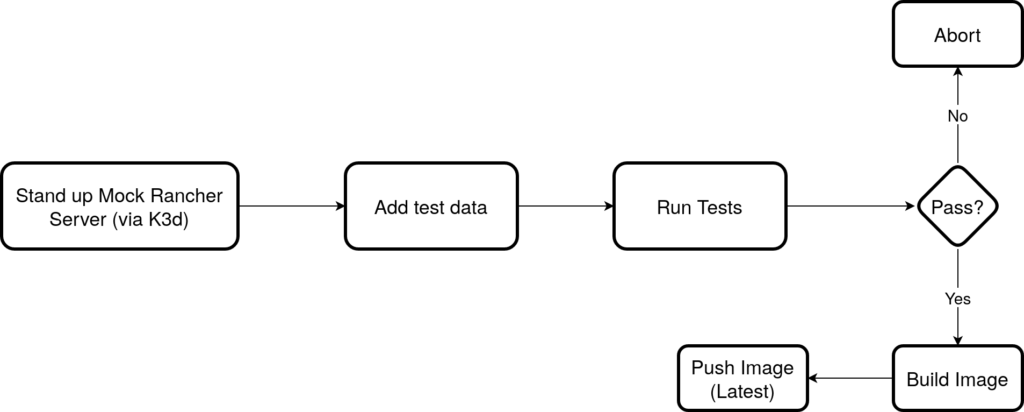
Previous CI workflow
The flowchart below outlines the existing process. Whilst automated, pushing directly to latest is bad practice.
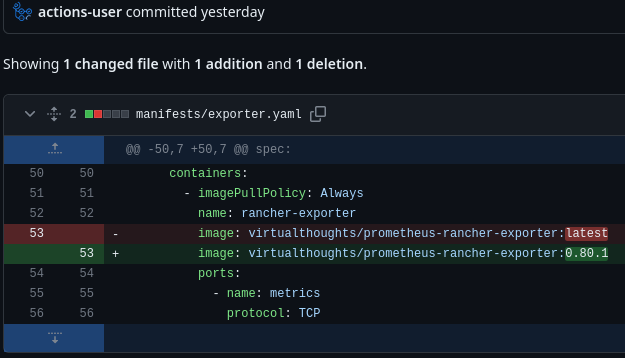
To improve this. Several additional steps were added. First of which acquires the latest, versioned image of the exporter and saves it to the $GITHUB_OUTPUT environment
Referencing this, the next version can be generated based on MAJOR.MINOR.PATCH. Incrementing the PATCH version. In the future, this will be modified to add more flexibility to change MAJOR and MINOR versions.
- name: Increment version
id: increment_version
run: |
# Increment the retrieved version
echo "updated_version=$(echo "${{ steps.get_version.outputs.image_version }}" | awk -F. -v OFS=. '{$NF++;print}')" >> $GITHUB_OUTPUT
With the version generated, the subsequent step can tag and push both the incremented version, and latest.
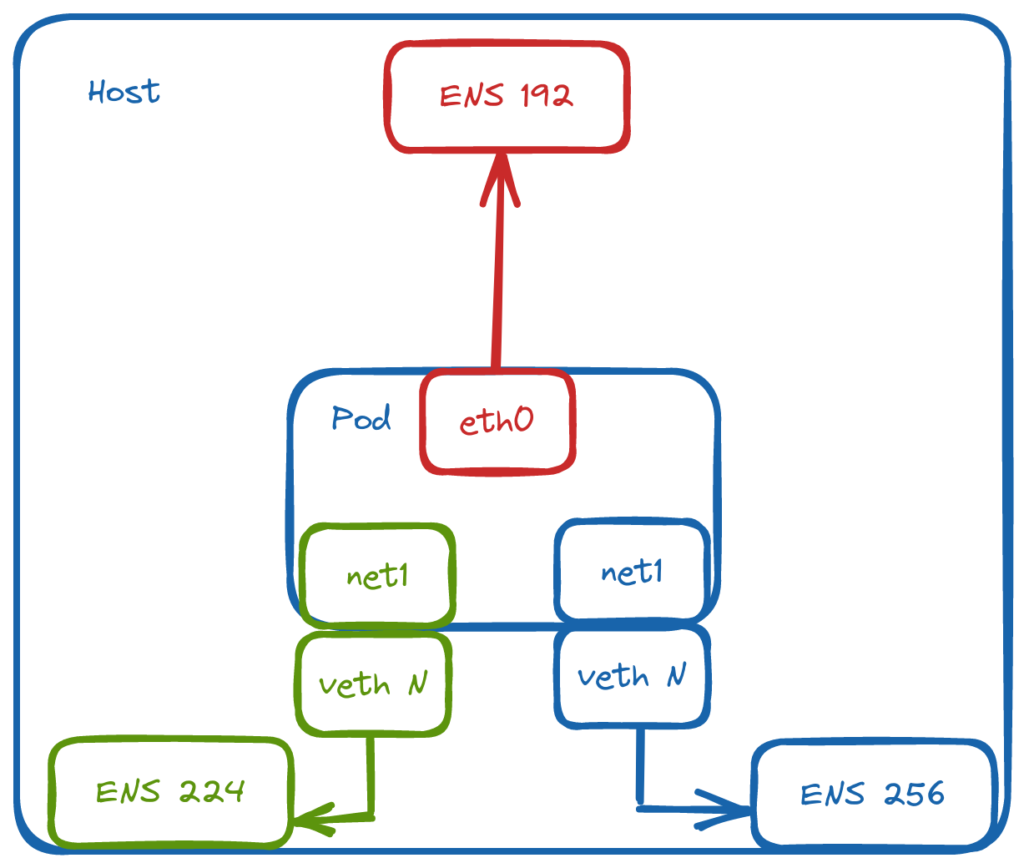
From my experience, some environments necessitate leveraging multiple NICs on Kubernetes worker nodes as well as the underlying Pods. Because of this, I wanted to create a test environment to experiment with this kind of setup. Although more common in bare metal environments, I’ll create a virtualised equivalent.
Planning
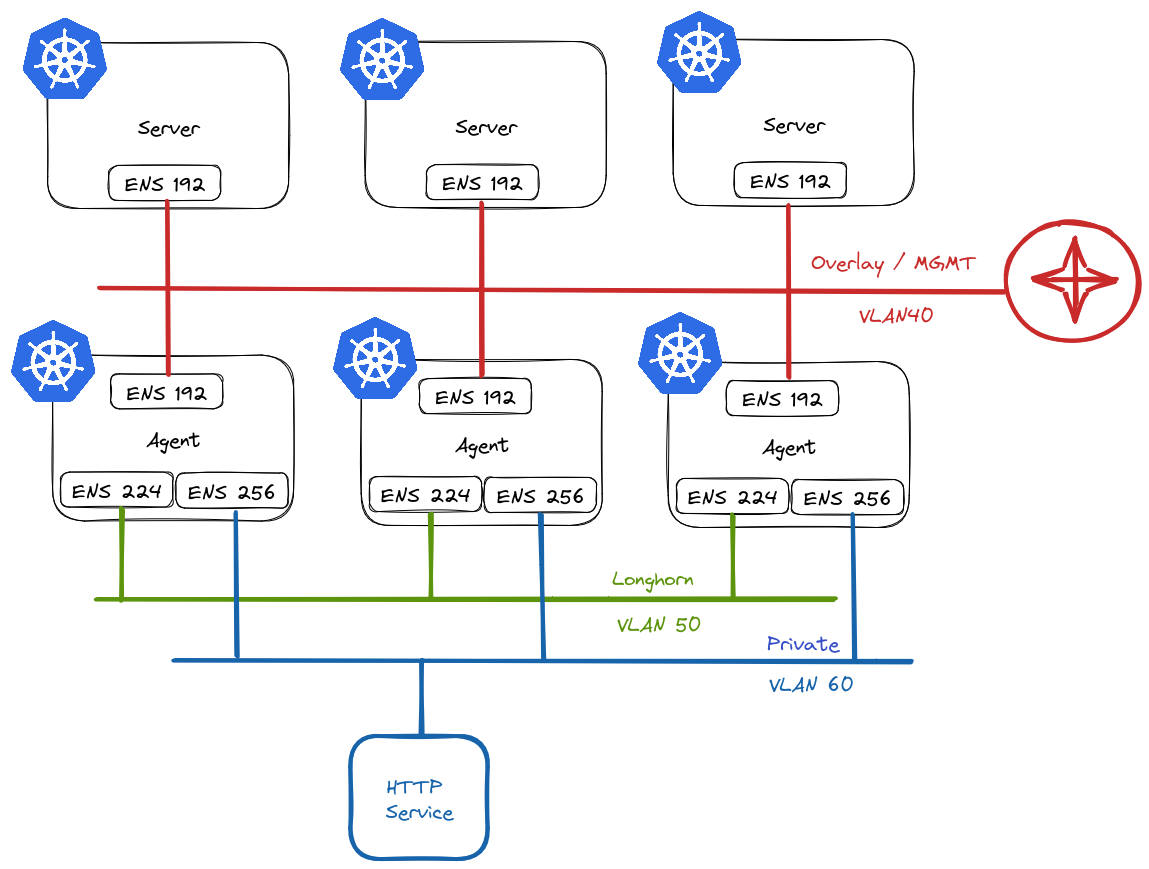
This is what I have in mind:
In RKE2 vernacular, we refer to nodes that assume etcd and/or control plane roles as servers, and worker nodes as agents.
Server Nodes
Server nodes will not run any workloads. Therefore, they only require 1 NIC. This will reside on VLAN40 in my environment and will act as the overlay/management network for my cluster and will be used for node <-> node communication.
Agent Nodes
Agent nodes will be connected to multiple networks:
VLAN40 – Used for node <-> node communication.
VLAN50 – Used exclusively by Longhorn for replication traffic. Longhorn is a cloud-native distributed block storage solution for Kubernetes.
VLAN60 – Provide access to ancillary services.
Creating Nodes
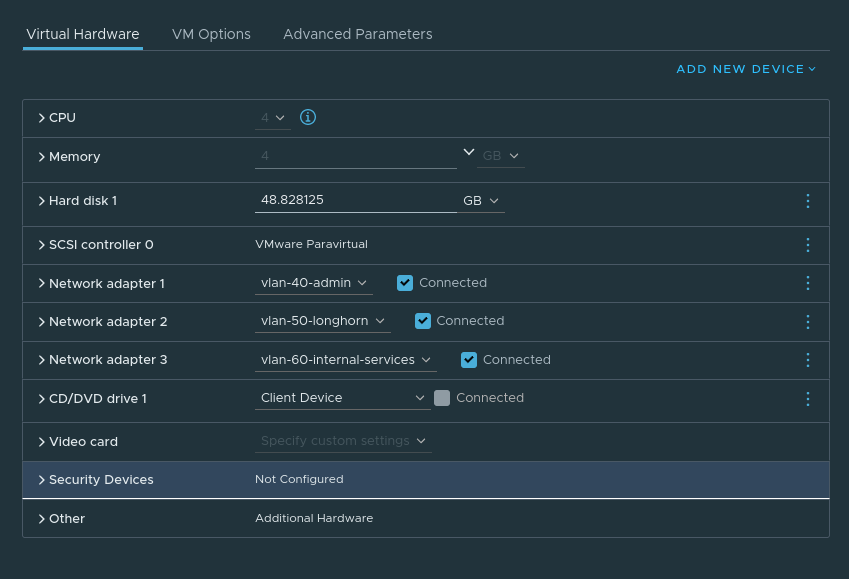
For the purposes of experimenting, I will create my VMs first.
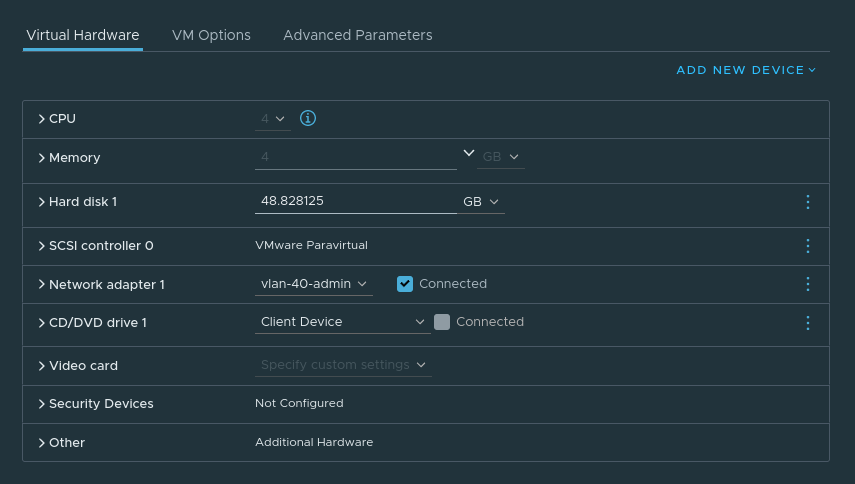
Server VM config:
Agent VM Config:
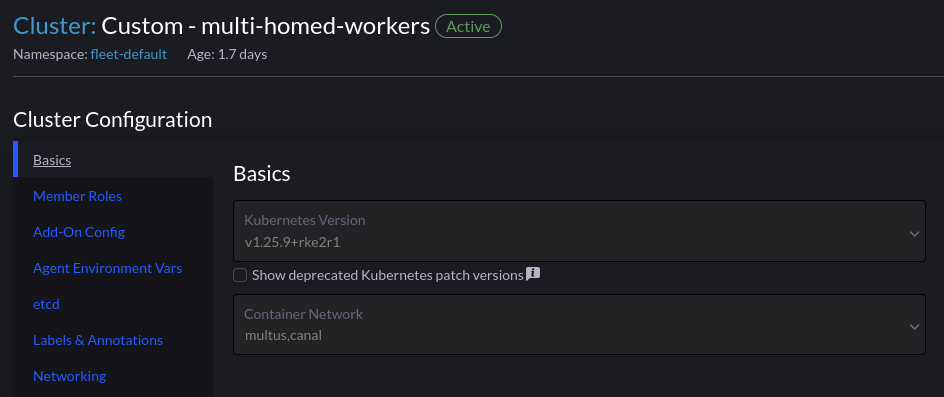
Rancher Cluster Configuration
Using Multus is as simple as selecting it from the dropdown list of CNI’s. We have to have an existing CNI for cluster networking, which is Canal in this example
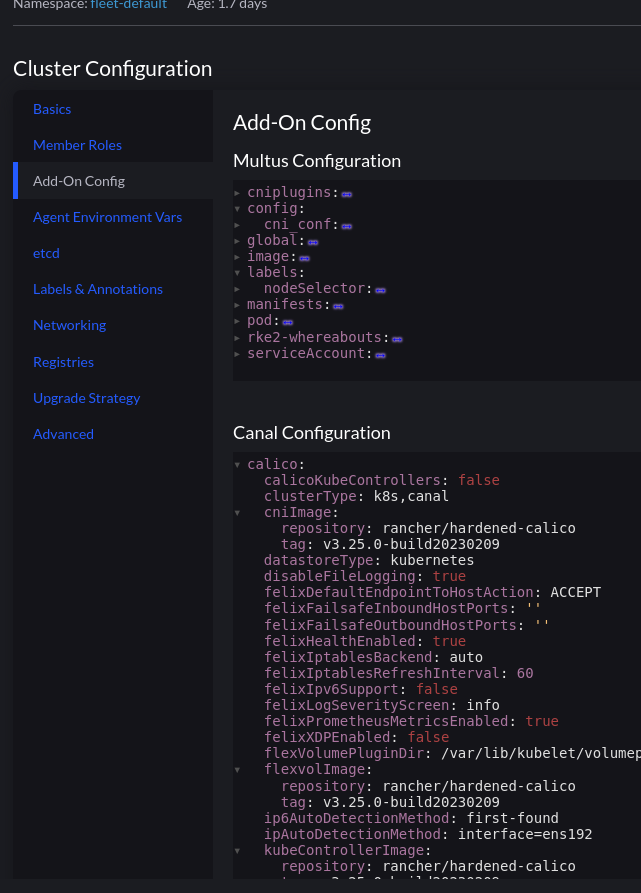
The section “Add-On Config” enables us to make changes to the various addons for our cluster:
Multus is not a CNI in itself, but a meta CNI plugin, enabling the use of multiple CNI’s in a Kubernetes cluster. At this point we have a functioning cluster with an overlay network in place for cluster communication, and every Pod will have a interface on that network. So which other CNI’s can we use?
Out of the box, we can query the /opt/cni/bin directory for available plugins. You can also add additional CNI’s if you wish.
For this environment, macvlan will be used. It provides MAC addresses directly to Pod interfaces which makes it simple to integrate with network services like DHCP.
Defining the Networks
Through NetworkAttachmentDefinition objects, we can define the respective networks and bridge them to named, physical interfaces on the host:
root@net-tools:/# ip addr show
3: eth0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 1a:57:1a:c1:bf:f3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.42.5.27/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::1857:1aff:fec1:bff3/64 scope link
valid_lft forever preferred_lft forever
4: net1@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether aa:70:ab:b6:7a:86 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.50.40/24 brd 172.16.50.255 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::a870:abff:feb6:7a86/64 scope link
valid_lft forever preferred_lft forever
5: net2@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 62:a6:51:84:a9:30 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.60.30/24 brd 172.16.60.255 scope global net2
valid_lft forever preferred_lft forever
inet6 fe80::60a6:51ff:fe84:a930/64 scope link
valid_lft forever preferred_lft forever
root@net-tools:/# ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
172.16.50.0/24 dev net1 proto kernel scope link src 172.16.50.40
172.16.60.0/24 dev net2 proto kernel scope link src 172.16.60.30
Testing access to a service on net2:
root@net-tools:/# curl 172.16.60.31
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
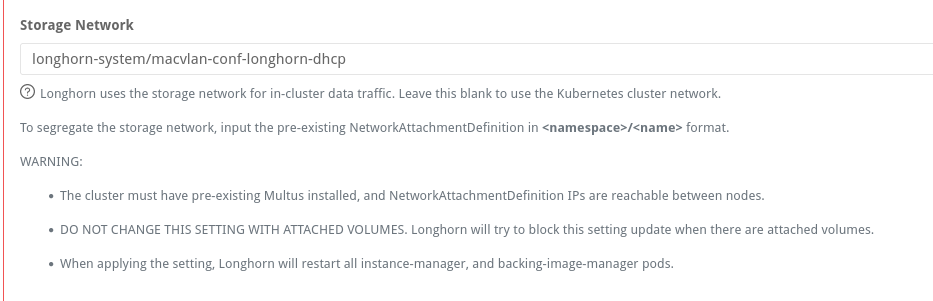
Configuring Longhorn
Longhorn has a config setting to define the network used for storage operations:
If setting this post-install, the instance-manager pods will restart and attach a new interface:
instance-manager-e-437ba600ca8a15720f049790071aac70:/ # ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if51: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether fe:da:f1:04:81:67 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.42.1.58/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::fcda:f1ff:fe04:8167/64 scope link
valid_lft forever preferred_lft forever
4: lhnet1@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 12:90:50:15:04:c7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.50.34/24 brd 172.16.50.255 scope global lhnet1
valid_lft forever preferred_lft forever
inet6 fe80::1090:50ff:fe15:4c7/64 scope link
valid_lft forever preferred_lft forever
Rancher leverages cloud-init for the provisioning of Virtual Machines on a number of infrastructure providers, as below:
I recently encountered an issue whereby vSphere based clusters using an Ubuntu VM template would successfully provision, but SLES based VM templates would not.
What does Rancher use cloud-init for?
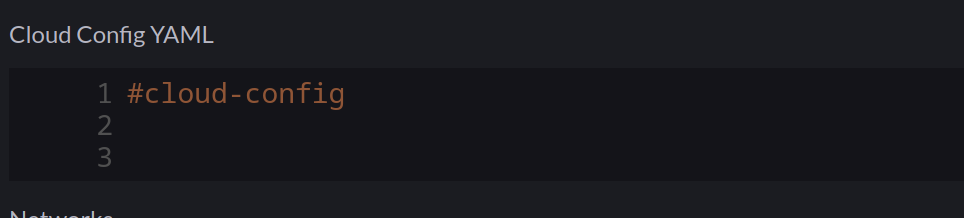
This is covered in the Masterclass session I co-hosted, but as a refresher, particularly with the vSphere driver, Rancher will mount an ISO image to the VM to deliver the user-data portion of a cloud-init configuration. The contents of which look like this:
Note: This is automatically generated, any additional cloud-init config you include in the cluster configuration (below) gets merged with the above.
It saves a script with write_files and then runs this with runcmd – this will install the rancher-system-agent service and begin the process of installing RKE2/K3s.
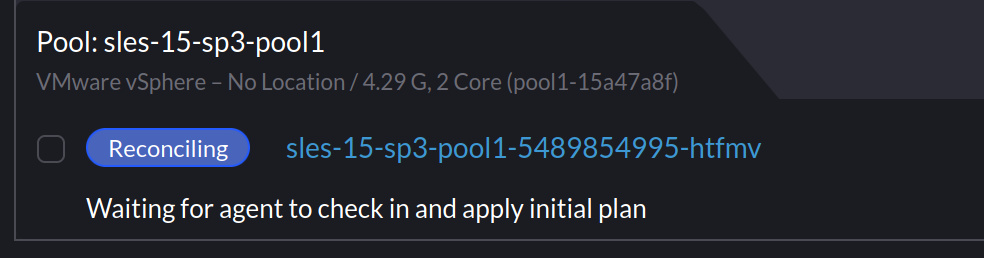
The Issue
When I provisioned SLES based clusters using my existing Packer template, Rancher would indicate it was waiting for the agent to check in:
Investigating
Thinking cloud-init didn’t ingest the config, I ssh’d into the node to do some debugging. I noticed that the node name had changed:
Inspecting user-data.txt from that directory also matched what was in the mounted ISO. I could also see /usr/local/custom_script/install.sh was created, but nothing indicated that it was executed. It appeared everything else from the cloud-init file was processed – SSH keys, groups, writing the script, etc, but nothing from runcmd was executed.
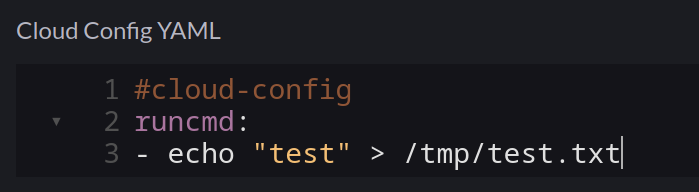
I ruled out the script by creating a new cluster and adding my own command:
As expected, this was merged into the user-data.iso file mounted to the VM, but /tmp/test.txt didn’t exist, so it was never executed.
Checking cloud-init logs
Cloud-Init has an easy way to collect logs – the cloud-init collect-logs command, This will generate a tarball:
sles-15-sp3-pool1-15a47a8f-xcspb:/ # cloud-init collect-logs
Wrote /cloud-init.tar.gz
I noted in cloud-init.log I could see the script file being saved:
2023-01-18 09:56:22,917 - helpers.py[DEBUG]: Running config-write-files using lock (<FileLock using file '/var/lib/cloud/instances/nocloud/sem/config_write_files'>)
2023-01-18 09:56:22,927 - util.py[DEBUG]: Writing to /usr/local/custom_script/install.sh - wb: [644] 29800 bytes
2023-01-18 09:56:22,928 - util.py[DEBUG]: Changing the ownership of /usr/local/custom_script/install.sh to 0:0
But nothing indicating it was executed.
I decided to extrapolate a list of all the cloud-init modules that were initiated:
Outside of the log bundle, /etc/cloud/cloud.cfg includes the configuration for cloud-init. having suspected the runcmd module may not be loaded, I checked, but it was present:
# The modules that run in the 'config' stage
cloud_config_modules:
- ssh-import-id
- locale
- set-passwords
- zypper-add-repo
- ntp
- timezone
- disable-ec2-metadata
- runcmd
However, I noticed that nothing from the cloud_config_modules block was mentioned in cloud-init.log. However, everything from cloud_init_modules was:
# The modules that run in the 'init' stage
cloud_init_modules:
- migrator
- seed_random
- bootcmd
- write-files
- growpart
- resizefs
- disk_setup
- mounts
- set_hostname
- update_hostname
- update_etc_hosts
- ca-certs
- rsyslog
- users-groups
- ssh
So, it appeared the entire cloud_config_modulesstep wasn’t running. Weird.
Fixing
After speaking with someone from the cloud-init community, I found out that there are several cloud-init services that exist on a host machine. Each dedicated to a specific step.
The cloud-config service was not enabled and therefore would not run any of the related modules. To rectify, I added the following to my Packer script when building the template: